Capítulo 12 - AJAX y más AJAX
Entendiendo HTTP/s
Http (Hypertext Transfer Protocol) es un protocolo de comunicación que utilizamos en nuestro día a día. Una de sus características clave es que no mantiene el estado, que ocasiona que tengamos que buscar alternativas para ello como las cookies, localStorage, etc...
Como curiosidad la versión más utilizada de este protocolo es la 1.1 de 1999, aunque recientemente, tenemos ya liberada la versión 2 que incluye muchas mejoras en el empaquetamiento y transporte de la información.
La parte clave a la hora de entender este protocolo, es que sigue un esquema petición-respuesta entre cliente y servidor, que hace que tengamos que refrescar la página para poder recibir la nueva información. Tal como funcionaba la web a principios del dos mil...
Si nos adentramos un poco más, veremos que esa peticion-respuesta, básicamente se compone de mensajes con una estructura muy determinada.
Línea inicial En la petición se especifica el método utilizado. En la respuesta se especifica un código de respuesta.
Cabecera Podremos encontrar todos los metadatos propios de la petición y la respuesta.
Cuerpo Esta parte es opcional y contiene por ejemplo html, css... textos planos, lo que sea en si el mensaje desde el servidor, así como desde el cliente.
Métodos
Cuando navegamos por la web utilizando el navegador por defecto, siempre estamos haciendo uso del método GET, pero existen gran cantidad de métodos con lo que poder hacer las peticiones.
Esto es importante, ya que desde las peticiones AJAX podremos especificar el método que utilizaremos, con lo que si estamos trabajando con una API REST, veremos que existe cierta "correlación" entre las rutas y los métodos usados.
Los métodos más utilizados son GET, POST (típico de formularios), PUT y DELETE.
Códigos de error
Cuando nos llega la respuesta del servidor, siempre viene acompañada de un código numérico que nos confirma el resultado de la petición, por ejemplo, el mítico error 404, que nos habremos encontrado en multitud de ocasiones navegando por la red.
Estos códigos de estado pueden dividirse en cinco categorías principales:
- 1xx Informativas.
- 2xx Peticiones Correctas.
- 3xx Redirecciones.
- 4xx Errores Cliente.
- 5xx Errores Servidor.
Siendo especialmente importantes para nosotros, los 4xx y los 5xx, ya que nos indican errores que están sucediendo y esto seguramente derive en un tráfico de datos erróneo.
Información
Aquí podéis encontrar la lista completa y la especificación.
Misterioso estado 418
Existen algunos códigos tan increíbles como 418. I´m a teapot.
Trabajando con APIs
Es innegable que cada día es más popular, escuchar términos como API, API REST... esto se debe a la manera de hacer la web hoy en día, con un gran desacoplamiento de cliente y servidor, que permite a un mismo backend, dar soporte a multiples soluciones de front, ya sean web, móviles, Internet Of Things (IoT)... e incluso otros backends.
Para hacer que todo esto fluya, es necesario comprender que juegan muchos factores claves como:
Normalmente en el mundo de la web cuando nos referimos a una API, casi siempre hablamos de una API REST, que nos permite a través de una serie de urls y siguiendo una metodología CRUD, trabajar con un backend desde el cliente.
Esto permite conseguir datos (peticiones GET), actualizar datos (peticiones PUT), crear nuevos datos (peticiones POST) y eliminar datos (peticiones Delete).
En la mayoría de los casos, el intercambio de información entre el cliente y servidor se realiza utilizando un formato de intercambio de datos conocido como JSON y no XML como antiguamente. De todo esto hablaremos a lo largo de este último capítulo.
Información
Para ilustrar un poco el ejemplo, te invito a visitar jsonplaceholder que es una especie de Lorem Ipsum para peticiones Ajax.
Supongamos que nuestro backend es un blog, y queremos crear, leer, actualizar y borrar posts. Nuestras rutas serían algo así:
Petición GET a api.loremblog.com/posts
Nos devuelve un JSON con todos los post disponibles.
Petición POST a api.loremblog.com/posts
Nos crea una nueva entrada en la base de datos, con los datos en JSON que le hemos pasado
Petición PUT a api.loremblog.com/posts/hello
Nos permite actualizar la entrada (numero/nombre hello) con los datos JSON que hemos pasado.
Petición DELETE a api.loremblog.com/posts/hello
Nos permite borrar la entrada (numero/nombre hello).
Información
Peticiones AJAX
Ya hemos visto que las peticiones Ajax son la esencia en la web de hoy, pero siempre que las utilicemos, debemos recordar, que nosotros somos consumidores/generadores de datos y que nuestra aplicación, está dependiendo de manera permanente de otros sistemas.
Esto quiere decir, que puede haber errores en su código, que hagan que las respuestas a nuestras peticiones no traigan los datos como esperamos. Por tanto, tendremos que hacer un esfuerzo adicional para validar todos los datos que recibimos. En ocasiones la documentación sobre la API, puede ser poco precisa o estar desfasada... dejándonos en una situación muy comprometida.
Pero la mayoría de servicios grandes o empresas que orientan sus líneas de negocio al API suelen dar un buen servicio. Recordar también que existen APIs de pago. En ocasiones esto puede resultar complicado, si estamos desarrollando, tenemos que hacer muchas consultas y se dispone de poco presupuesto.
Nosotros recomendamos, crear un sistema de archivos JSON que almacene ciertos datos estáticos, que sean iguales o muy similares a los que esperamos recibir de la API. Así podremos maquetar y desarrollar sin consumir realmente llamadas. Esto es especialmente útil, para sistemas muy caros como APIs de Inteligencia Artificial como Servicio (AIaaS).

Errores más comunes (por código)
Referimos a continuación una lista de los errores más comunes, y de algunas soluciones cuando no encontramos mucha documentación disponible sobre una API en concreto.
Respuesta 200 OK. Este es el código esperado... y todo marcha bien.
Respuesta 204 Sin contenido. No hemos enviado los datos, pero la petición ha resultado exitosa, seguramente con datos por defecto.
Respuesta 401 No autorizado. Hemos olvidado utilizar el token. O nuestro token no está correctamente configurado.
Respuesta 403 Prohibido. No tenemos el token/acceso correcto. Puede ser que intentemos modificar elementos que no sean de nuestra competencia, como la configuración de otros usuarios, etc...
Respuesta 404 No encontrado. Hemos apuntado a una ruta que no existe. Revisa la documentación.
Respuesta 409 Conflicto, ya existe. Hemos intentado crear dos veces el mismo elemento, esto suele pasar si realizamos una doble llamada Ajax, por error. Típico de peticiones POST.
JSON
Antes de realizar nuestra primera llamada Ajax, veamos como trabajar con JSON.
Para la visualización, validación y conversión dinámica de datos contamos con algunas herramientas muy útiles.
Información
Es importante recordar que algunas respuesta JSON, pueden contener hasta varios megas de información. Necesitaras herramientas de visualización adicionales más allá de la consola de tu navegador.
El navegador nos aporta dos formas básicas de interactuar con datos JSON.
Que analiza la cadena JSON, validándola y retornando los valores como un dato válido de JavaScript. Lo más habitual es un objeto o array.
var objeto = JSON.parse('{"test": true}');
var lista = JSON.parse('[true, "NO", 23]');
var booleano = JSON.parse('false');
var texto = JSON.parse('"cadena!"');
Analiza los valores y retorna una cadena en formato JSON.
var objetoJSON = JSON.stringify({"test": true});
var listaJSON = JSON.stringify([true, "NO", 23]);
var booleanoJSON = JSON.stringify(false);
var textoJSON = JSON.stringify("cadena!");
Peticiones
La mecánica de las peticiones es realmente sencilla. Simplemente necesitamos saber a que URL vamos a realizar la petición, que método vamos a utilizar (GET, POST, PUT o DELETE) y con que función (callback) manejaremos los datos de vuelta.
Información
Lógicamente las peticiones Ajax son asíncronas por naturaleza. Si aún tienes dudas, sobre los callbacks y el manejo de la sincronía, este es un gran momento para retroceder al capítulo anterior y repasar esos conceptos antes de seguir.
Si estáis familiarizados con JQuery, las peticiones Ajax son algo muy trivial, gracias a jQuery.ajax(). Veamos el siguiente ejemplo:
$.ajax({
dataType: "json",
url: "<---URL---->",
})
.done(function( data, textStatus, jqXHR ) {
console.log( "La solicitud se ha completado correctamente." );
console.log( data );
})
.fail(function( jqXHR, textStatus, errorThrown ) {
console.log( "La solicitud a fallado: " + textStatus);
});
No recargamos pero somos asíncronos.
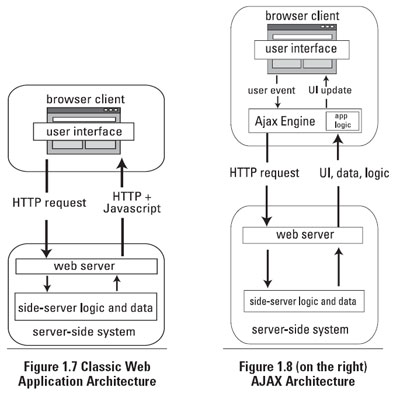
Como puedes ver, ya no es necesario recargar la página como antes, ya que el navegador se encarga de hacer la petición y gestionarla en un segundo plano. Ahora veremos como se hace con Vanilla.js, verás que realmente se entiende mejor el proceso y parece menos mágico que con JQuery.
Hablemos de XMLHttpRequest
Para poder realizar peticiones Ajax, de manera nativa, los navegadores implementan un objeto desde el que podremos realizar las peticiones, llamado XMLHttpRequest.
Tiene sus propios eventos:
Y sus propios estados de petición:
- 0 uninitialized
- 1 loading
- 2 loaded
- 3 interactive
- 4 complete
Mejor veamos como funciona con un ejemplo real y luego explicamos como gestionar algo que parece tan complejo, pero que realmente es sencillo.
Para este ejemplo hemos decidido traer los datos de la película Hackers, que además os recomiendo ver.
Para ello utilizaremos OMBd Api... una vez leída la documentación, sabremos que solo necesitamos apuntar a esta url, http://www.omdbapi.com/?t=Hackers&y=&plot=short&r=json.
var url = "http://www.omdbapi.com/?t=Hackers&y=&plot=short&r=json";
var xmlHttp = new XMLHttpRequest();
xmlHttp.onreadystatechange = function() {
if (xmlHttp.readyState === 4)
if(xmlHttp.status === 200) {
console.info(JSON.parse(xmlHttp.responseText));
} else if (xmlHttp.status === 404) {
console.error("ERROR! 404");
console.info(JSON.parse(xmlHttp.responseText));
}
};
xmlHttp.open("GET", url, true);
xmlHttp.send();
Viendo el código es mucho más sencillo...
Vamos por pasos:
- Línea 1: Primero definimos la URL.
- Linea 2: Luego instanciamos XMLHttpRequest, igual que hacíamos con Date en capítulos anteriores.
- Linea 4: Cada vez que cambiemos de estado en nuestra petición Ajax, el navegador ejecutará xmlHttp.onreadystatechange .
- Linea 6: Filtramos por el xmlHttp.readyState, y esperamos al 4 (completado).. obviando todo lo demás.
- Linea 7: Una vez confirmamos que se terminó toda la gestión de Ajax, pasamos a analizar los datos recibidos. Filtrando por código de estado con xmlHttp.status, y parseando o alertando al usuario del error en función de las circunstancias.
- Linea 14: Abrimos la petición con la url y el método deseado.
- Linea 15: Ejecutamos la petición.
CORS
Un problema clásico a tener en cuenta es la posibilidad de que CORS, no esté habilitado en el servidor.
CORS básicamente, es un parámetro que se envía desde las cabeceras HTTP del servidor y nos permite realizar peticiones AJAX. Existen algunos sitios web, que a pesar de tener, una API funcionando no han habilitado esta configuración:
"Access-Control-Allow-Origin", "*"
"Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept"
Y por ello, cualquier petición que hagamos desde el navegador cliente no podrá realizarse.
La mejor solución, es comunicarnos con los responsables de la API y facilitarles este link, donde Monsur Hossain y Michael Hausenblas, explican como realizar las configuraciones adecuadas en muchos entornos.
Si por desgracia esta opción está descartada, no pasa nada.... existen más posibilidades.
La primera y más útil es crear/configurar/usar un proxy. La idea del proxy, es que realice una petición capturando esos datos y enviándolos de nuevo, teniendo CORS habilitado en la cabecera, de tal forma que podremos hacer peticiones Ajax, aunque tengamos que pasar por nuestro servidor.
Lógicamente nos plantea un problema de tráfico, en nuestro servidor y una lentitud en nuestras peticiones, pero al menos podremos hacer las peticiones.
Información
Antes de configurar un proxy, puedes usar Crossorigin para prototipar -es un proyecto Open Source- y podrás adaptarlo fácilmente a tus necesidades.